
مع التوسع المتسارع في تطبيقات الذكاء الاصطناعي، بدأت مصطلحات تقنية جديدة تدخل إلى النقاشات المهنية بشكل متكرر، ومن أبرزها قواعد بيانات المتجهات (Vector Database). وقد يبدو الاسم معقدًا للوهلة الأولى، لكنه يشير في جوهره إلى فكرة عملية ومهمة: كيف يمكن للأنظمة أن تبحث عن المعلومات وفق المعنى، لا وفق الكلمات المطابقة فقط؟ هنا تظهر قيمة هذا النوع من قواعد البيانات، الذي صُمم لدعم البحث الدلالي والتعامل مع كميات كبيرة من البيانات غير المنظمة بكفاءة أعلى من الأساليب التقليدية. فبدلًا من الاكتفاء بمطابقة الكلمات حرفيًا، تعتمد هذه القواعد على تمثيل المحتوى في صورة نماذج رقمية تعبر عن دلالته وسياقه، ما يسمح بالوصول إلى نتائج أكثر قربًا من مقصد المستخدم، حتى لو اختلفت الألفاظ المستخدمة في السؤال أو في المادة المخزنة.
وتزداد أهمية هذا المفهوم في تخصص الصحافة على نحو خاص، لأن العمل الصحفي يعتمد بدرجة كبيرة على الوصول السريع إلى المعلومات الدقيقة داخل كم واسع من المواد غير المنظمة، مثل التقارير السابقة، والمقابلات، والتصريحات، والأرشيفات النصية، والمرئية. ومن خلال البحث الدلالي الذي تتيحه قواعد بيانات المتجهات، يصبح بإمكان الصحفي العثور على المواد الأقرب إلى موضوعه أو سؤاله حتى إن لم يستخدم الكلمات نفسها الواردة في المصدر، وهو ما يدعم التحقق من المعلومات، وربط الأحداث بسياقاتها، واكتشاف الروابط بين الموضوعات المتشابهة. كما تسهم هذه القواعد في تحسين إدارة المحتوى داخل المؤسسات الإعلامية، وتسهيل بناء أدوات بحث أكثر ذكاءً تساعد الصحفيين على إنتاج محتوى أعمق وأسرع وأكثر قدرة على خدمة الجمهور.
مثال: تغطية أزمة ارتفاع الأسعار في الولايات المتحدة
إذا كنت تعد تقريرًا صحفيًا عن ارتفاع الأسعار، فقد لا تبحث فقط عن عبارة “ارتفاع الأسعار” نفسها، بل قد تحتاج أيضًا إلى الوصول إلى مواد سابقة تناولت موضوعات قريبة مثل التضخم، وتكاليف المعيشة، وأسعار السلع الأساسية، وشكاوى المستهلكين، وتصريحات الجهات الرسمية. هنا تساعد قواعد بيانات المتجهات في العثور على المحتوى المرتبط بالموضوع من حيث المعنى والسياق، حتى إن اختلفت الكلمات المستخدمة في كل مادة. وهذا يمنح الصحفي قدرة أكبر على جمع خلفية متماسكة، ومقارنة التغطيات السابقة، وتتبع تطور القضية زمنيًا، بما يسهم في إعداد تقرير أكثر دقة وعمقًا.
ببساطة، تقوم قواعد بيانات المتجهات بتخزين البيانات في شكل تمثيلات رقمية تُعرف بالمتجهات. هذه التمثيلات لا تحفظ النص أو الصورة أو الصوت بصيغتها الأصلية فقط، بل تعكس معناها أو خصائصها في صورة أرقام يمكن مقارنتها رياضيًا. وعندما يطرح المستخدم سؤالًا أو يبحث عن معلومة، يمكن للنظام أن يجد العناصر الأقرب في المعنى، حتى لو لم تتطابق الكلمات المستخدمة بشكل حرفي. لهذا السبب تُعد هذه القواعد مناسبة جدًا للبحث الذكي، وأنظمة التوصية، والمساعدات الرقمية الحديثة.
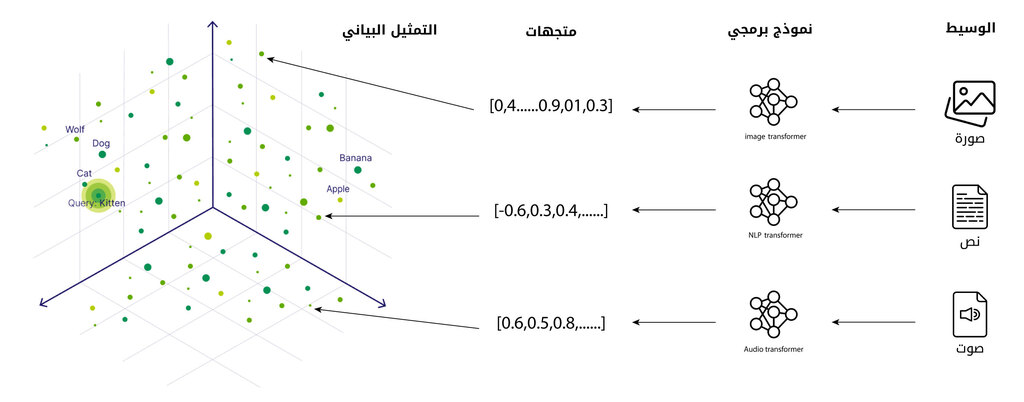
على سبيل المثال، إذا أدخلنا الجملة: “ارتفعت أسعار الغذاء هذا الشهر”، فإن النظام يبدأ أولًا بتقسيمها إلى وحدات لغوية أصغر مثل: “ارتفعت”، “أسعار”، “الغذاء”، “هذا”، “الشهر”. بعد ذلك لا ينظر إلى كل كلمة بمعزل عن غيرها، بل يحلل موقعها داخل الجملة والعلاقة بينها؛ فكلمة “أسعار” ترتبط هنا بفكرة اقتصادية، وكلمة “الغذاء” تحدد المجال، بينما تعطي عبارة “هذا الشهر” بعدًا زمنيًا. ثم يستخدم النموذج هذه العلاقات ليحول الجملة كلها إلى تمثيل رقمي على شكل مجموعة من القيم العددية التي تعبر عن معناها العام، مثل قربها من مفاهيم: التضخم، المعيشة، والسلع الأساسية.
ويمكن تبسيط الفكرة بالقول إن الجملة لا تُخزن كنص فقط، بل كإحداثيات رقمية داخل مساحة معنوية؛ فإذا وُجد نص آخر مثل “زادت تكاليف المواد الغذائية مؤخرًا”، فقد يحصل على تمثيل رقمي قريب، لأن المعنى متشابه حتى لو اختلفت الكلمات. وبالطريقة نفسها، إذا أُدخلت صورة لرفوف متجر تحمل بطاقات أسعار مرتفعة، فإن النموذج البصري يحلل عناصرها مثل الرفوف، والأرقام، والمنتجات، وتوزيع الألوان والأشكال، ثم يحول هذه السمات إلى تمثيل رقمي يمكن مقارنته بتمثيلات نصوص أو صور أخرى. وهكذا تصبح المقارنة قائمة على المعنى والخصائص، لا على التطابق الحرفي فقط.
الفرق الأساسي بين قواعد بيانات المتجهات وقواعد البيانات التقليدية يكمن في طبيعة البحث. فالقواعد التقليدية تتفوق في التعامل مع البيانات المنظمة، مثل الجداول والسجلات والأرقام، وتعتمد غالبًا على التطابق الدقيق أو شروط البحث المحددة. أما قواعد بيانات المتجهات، فقد صُممت للتعامل مع التشابه الدلالي داخل بيانات أكثر تعقيدًا، مثل المستندات الطويلة، والمحادثات، والصور، والمحتوى غير المنظم عمومًا. وبدلًا من السؤال: هل هذه الكلمة موجودة؟ يصبح السؤال: ما المحتوى الأقرب إلى هذا المعنى؟
ازدادت أهمية قواعد بيانات المتجهات مع صعود نماذج الذكاء الاصطناعي التوليدي والبحث الدلالي، لأن هذه الأنظمة تحتاج إلى الوصول السريع إلى معلومات ذات صلة بالسياق. فعندما يُحوَّل السؤال والمحتوى إلى متجهات، يصبح بالإمكان قياس مدى التقارب بينهما واسترجاع النتائج الأكثر ارتباطًا بالمعنى. وتؤكد المراجع التقنية من جهات مثل IBM وSAP أن هذا النوع من البنية يدعم تطبيقات الذكاء الاصطناعي الحديثة لأنه يتيح استرجاعًا أسرع وأكثر ملاءمة للبيانات غير المنظمة، وهي الفئة التي تتنامى قيمتها داخل المؤسسات والمنصات الرقمية.
وتظهر الاستخدامات العملية لقواعد بيانات المتجهات في مجالات كثيرة. فهي تُستخدم في تحسين نتائج البحث داخل المواقع والمنصات، وفي أنظمة التوصية التي تقترح محتوى أو منتجات متقاربة مع اهتمامات المستخدم، وفي المساعدات الذكية التي تحتاج إلى استحضار أجزاء من المعرفة بسرعة عند توليد الإجابات. كما تلعب دورًا مهمًا في التطبيقات التي تعتمد على البحث داخل مستندات كثيرة أو قواعد معرفة ضخمة، حيث لا يكون الاعتماد على الكلمات المفتاحية وحدها كافيًا لفهم المقصود الحقيقي من الاستعلام.
وبالنسبة لمتخصصي الاتصال، لا تنبع أهمية هذا المفهوم من جانبه التقني فحسب، بل من تأثيره المباشر في كيفية تنظيم المعرفة والوصول إلى الرسائل والمحتوى المناسب في الوقت المناسب. فكلما أصبحت أدوات البحث أكثر فهمًا للسياق والمعنى، زادت قدرة الفرق على إدارة المحتوى، وتحسين تجربة الجمهور، وبناء قنوات تواصل أكثر ذكاءً. كما أن فهم هذا المفهوم يساعد المتخصصين في الاتصال على مواكبة التحولات الرقمية، والتواصل مع الفرق التقنية بلغة أقرب إلى الواقع العملي بدلًا من الاكتفاء بالمصطلحات العامة.
في النهاية، يمكن النظر إلى قواعد بيانات المتجهات بوصفها استجابة تقنية لحاجة متزايدة إلى فهم المعنى داخل كم هائل من البيانات غير المنظمة. وهي لا تستبدل قواعد البيانات التقليدية، لكنها تكملها في الحالات التي يكون فيها السياق والتشابه الدلالي عاملين حاسمين. ومع استمرار توسع تطبيقات الذكاء الاصطناعي، يبدو أن هذا المفهوم سيبقى حاضرًا بقوة في النقاشات المهنية والتقنية على حد سواء.






